Category: Math
-
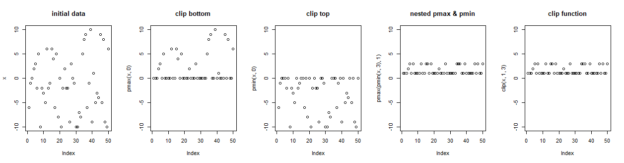
Equivalent of Numpy’s Clip function in R
Numpy’s clip function is a handy function that brings all data in a series into a range. For example, in machine learning, it is common to have activation functions that take a continuous range of values and bring them to a range like 0 to 1, or -1 to 1. In my case, I was…
-
Markov Chain Simulation
I’ve been reading up on Markov chains and related concepts. On the wikipedia page there is an example of a 2 state Markov process. I decided to simulate it in R and plot the mean of the means. Quick Code example here: The mean of means (of state e) is close to .36. If you…
-
The Math of Machine Learning
(hover for CC attribution) One of the challenges of data science in general is that it is a multi-disciplinary field. For any given problem, you may need skills in data extraction, data transformation, data cleaning, math, statistics, software engineering, data visualization, and the domain. And that list likely isn’t inclusive. One of the first questions…
-
Presentation on Linear Algebra in R
At our January meeting, I presented on Linear Algebra basics in R. I have been taking the Andrew Ng’s Stanford Machine Learning course. That course primarily uses Matlab (or Octave, and open source equivalent), and machine learning involves manipulating and calculating with matrices. Naturally, being an R person, I have been working with some of…
-
Mapping Functions in R
I have been buffing up on some areas of Math that I felt rusty in. One of the tools I was using was my old TI-82 calculator I used in high school. I even got the TI Connect software working where I could download screenshots, etc. You can put in data sets (see screen cap…