Category: Programming
-
8-bit CPUs
I’ve been doing some retro programming on the 2600 and learning 6502 assembly. Between that and some podcast listening, I was surprised to hear how much overlap and inspiration there was between the 8-bit processor families. I always thought they were very different. So I used claude and mermaidjs to come up with the following…
-
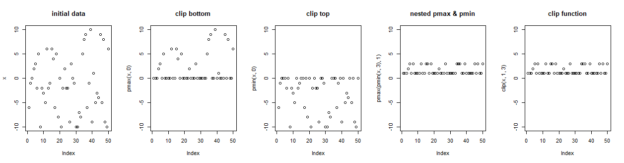
Equivalent of Numpy’s Clip function in R
Numpy’s clip function is a handy function that brings all data in a series into a range. For example, in machine learning, it is common to have activation functions that take a continuous range of values and bring them to a range like 0 to 1, or -1 to 1. In my case, I was…
-
Files and Pipes in R Video Demo
I’ve worked with various alternate file handlers in python before and wanted to explore the options in R. I was pleasantly surprised to find handlers prebuilt for tasks like compressing data. In addition, a pipe function is available to allow you to use less common commands on your file, like gpg for encryption. I put…
-
Installing pymc on OS X using homebrew
I’ve been working through the following book on Bayesian methods with an emphasis on the pymc library: However, pymc installation on OS X can be a bit of a pain. The issues comes down to fortran… I know. The version of gfortran in newer gcc implementations doesn’t work well with the pymc build, you need…
-
Installing TensorFlow on CentOS
Google released TensorFlow as open source for community use and improvement. From the site: “TensorFlow™ is an open source software library for numerical computation using data flow graphs.” The instructions on tensorflow.org are aimed at Ubuntu and OS X. I had a need to install it on CentOS so I documented the steps in a…