Category: Python
-
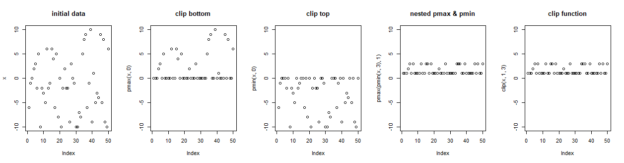
Equivalent of Numpy’s Clip function in R
Numpy’s clip function is a handy function that brings all data in a series into a range. For example, in machine learning, it is common to have activation functions that take a continuous range of values and bring them to a range like 0 to 1, or -1 to 1. In my case, I was…
-
Interview and Upcoming Projects
Here is a recent interview I did for CLK Tech. CLK Tech is a newsletter based out of Northeast Ohio, run by a couple of tech recruiters in the area. Topics span general career questions and data science in particular. In addition, I’m busy with a project that I look forward to announcing soon. It’s…
-
Installing pymc on OS X using homebrew
I’ve been working through the following book on Bayesian methods with an emphasis on the pymc library: However, pymc installation on OS X can be a bit of a pain. The issues comes down to fortran… I know. The version of gfortran in newer gcc implementations doesn’t work well with the pymc build, you need…
-
The Math of Machine Learning
(hover for CC attribution) One of the challenges of data science in general is that it is a multi-disciplinary field. For any given problem, you may need skills in data extraction, data transformation, data cleaning, math, statistics, software engineering, data visualization, and the domain. And that list likely isn’t inclusive. One of the first questions…
-
Machine Learning & Gradient Boosting w/xgboost
I presented at the Cleveland R User Group on using xgboost in R. Slides are available here. Code (jupyter notebooks) are here. Feedback welcome. Enjoy!