Tim’s Blog
-
Using AI to Rapidly Generate a Playlist
This weekend I was at my daughter’s dance recital and noticed some music I would like for the work day. While doing technical or involved work, I like music without words that is not too distracting. I love jazz, but find it taking my mind off my work often, so I listen to lofi, chillhop,…
-
Playing Pitfall the Mayan Adventure on a Modern Windows 11 PC
Pitfall the Mayan Adventure was on Genesis (MegaDrive), Super Nintendo, and PC for Windows 95. It requires the CD to be in the drive in order to read audio. I tried a variety of methods including virtualbox that worked to varying degrees. But I find a solution that provided a better gameplay experience and better…
-
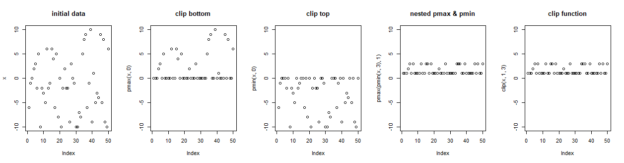
Equivalent of Numpy’s Clip function in R
Numpy’s clip function is a handy function that brings all data in a series into a range. For example, in machine learning, it is common to have activation functions that take a continuous range of values and bring them to a range like 0 to 1, or -1 to 1. In my case, I was…
-
Using Tensorboard with Multiple Model Runs
I tend to use Keras when doing deep learning, with tensorflow as the back-end. This allows use of tensorboard, a web interface that will chart loss and other metrics by training iteration, as well as visualize the computation graph. I noticed tensorboard has an area of the interface for showing different runs, but wasn’t able…
-
StirTrek 2018 Talk: Machine Learning in R
I had the chance to speak at StirTrek 2018 about Machine Learning in R. I have been to StirTrek before, but it’s been a few years. The conference has really grown, as there are over 2000 attendees now. I was in the 3:30 timeslot. I talked in a full theater and they broadcast the talk…
Got any book recommendations?