I’ve been making an effort to learn R for about a year. I have experimented with it on and off over the years, but this is first serious effort I’ve been making.
Whenever I am learning something, rather than just focusing on book examples, I try to come up with an example that is relevant to me and interesting. Doing that helps keep me motivated, and drives me to pick the things I want to know that are useful, and not just focus on the things that are revealed through examples. I would liken this to an experiment I heard a Khan Academy engineer talking about where students are exposed to various Logo drawings. Some of which have the source code available and some don’t. The ones without source serve as motivation and focus on principles that will build and challenge on what the student already knows.
In my case this means the following: if I’m going to work with Linear Models in R, I’m not just going to work with an example that lends itself to that data, but to be challenged to evaluate with variables might make a valid model and then test that fit with a critical eye.
In my case, I decided to try to not be the worst in my NFL Pick’em league this year. I usually do ok in the league, but I’m having a particularly bad year. The premise of the league is as follows. This league is only about picking game results, not like fantasy football. You pick every game each week, and you pick against the spread. The most correct picks win.
For those who don’t know what a spread is: it’s a gambling mechanism to get people to bet on both sides of a game. Bets are like stock purchases, you may not think about it every time you make a transaction but there needs to be someone taking a position on the other side. Many people assume the casino (or bookmaker) is taking the other position. They are trying not to take a position, they are really just a market-maker. The bookmaker attempts to make money by having a small profit margin (sometimes called overround) on the bets. In order to not take a position, they want as close to 50% of the betting population on each side of the bet. That way, each winner is paid using the losses of a loser. In order to accomplish that, they use a spread, or payout odds. In the case of a spread, they subtract a certain number of points from the favorite, to entice people to bet the underdog. If Denver plays Oakland, and the spread is Denver – 10, the bookmaker is saying that by subtracting 10 from Denver’s score, they think they will get an even market. If Denver wins by more than 10, the Denver betters are right. If they win by less than 10 or lose the game outright, the Oakland betters win. If Denver were to win by exactly 10, the bet is a push, and both sides get their original bet back.
Our league is not a gambling league in the sense of betting per game. You just pick all the games, and there is a prize at the end of the year for the most correct picks. It is run by a friend and I have been in the league for over 10 years now. So needless to say, I know the domain. Which in doing analysis is a huge leg-up. You can intuit pretty quickly if numbers look correct, or if a stat has meaning.
So the first step was to track results. I used google docs to keep track of my picks. It has an option to download spreadsheets as a csv file, which is a very friendly format for R to work with. If you want to try this with your picks, you can make a copy from here.
Now comes the R work. All the code is up on my github account. The first step was to get the data into a data frame, one of R’s most common structures. Picks.R does just that, and adds some calculated columns and gets calculates some general league trends. I wrote two functions condition_frequency and condition_percentage that can calculate almost all the required stats. They are functions that count the number of occurences of some condition, or a percentage. Both take functions for the condition, and can look at all picks, or be passed another function that is used to determine a subset to analyze. For instance, you can calculate the percentage of home teams that cover the spread when they are favored by passing a set condition that looks for results where the home team is favored, and a subset condition of the home team winning by more than the spread.
Output
Describe.R writes a markdown file that can produce html to show league trends and personal trends. The result looks like:
Next I decided to plot my results by week. The results are:
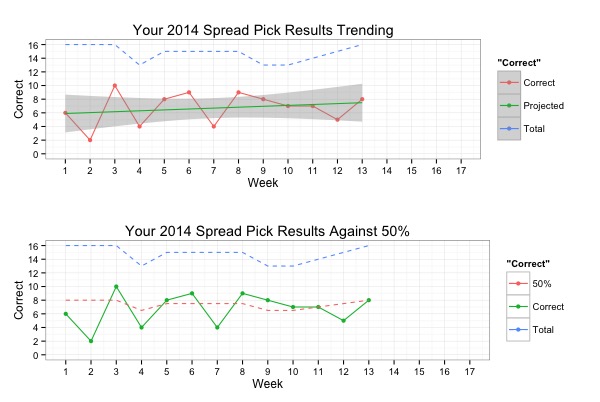
You can see I tried to apply a simple linear model to the results based on how many weeks of football I had to project how much better picking would get. That’s a questionable model to try, but it at least demonstrates your general trend.
In Teams.R there is a function unplayed_games that will give you relevant stats about each team in the games that don’t have scores yet.
So what did I learn?
I learned to use functions very effectively in R, and to try to take advantage of the way you can operate on entire vectors at the same time. (Data frame columns are vectors). I learned to work with Hadley Wickham’s dplyr and ggplot2 libraries, which are great for productivity once you understand the philosophy of how to work with those libraries.
A lot of the visual and transformation work was helped by a workshop the Cleveland R User Group held with Robert Kabacoff. He was a very good instructor and it really put a lot of pieces together for me about working with R.
What Next?
I’d like to get into clustering the data, and seeing how results vary by spread size. In addition, I’d like to try some machine learning. Train up models and see if the machine can predict better.
In particular, I’d like to bring team popularity into the model. Why? Remember the long-winded discussion of how and why bookmakers make spreads? Did you notice that the bookmaker isn’t trying to predict the most accurate line, they are trying to get 50% of the betters on each side. That means that there are opportunities for exploitation. The common example is large market (or popular) teams. Consider the Pittsburgh Steelers (which as a Bengals fan, I of course loathe but that is not the point…): The steelers have backer groups across the country and a huge following. If they were to play a team like Jacksonville that struggles to sell out their tickets, it is likely that there is a certain base that is going to bet on the Steelers simply because they are fans. In order to achieve that 50% balance, bookmakers are likely to skew the spread to overly favor Jacksonville. To make the less popular team a more attractive bet. Savvy data driven pickers end up taking the mathematical advantage at the expense of betters just playing favorites.
Also, I’d like to investigate ways to make the entire app more approachable. Could this be a shiny app that takes a url to a csv and present the user with results?
It’s been a fun project, and I’ve seen some improvement over the year. That said, I’ve had a rough picking year and certainly won’t finish in the money. But it’s kept my R learning journey moving along, and I’ve enjoyed it.