Category: R
-
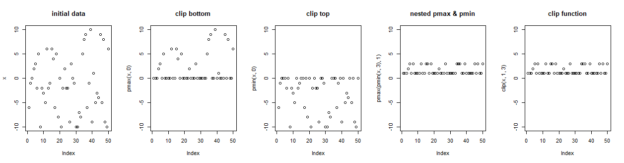
Equivalent of Numpy’s Clip function in R
Numpy’s clip function is a handy function that brings all data in a series into a range. For example, in machine learning, it is common to have activation functions that take a continuous range of values and bring them to a range like 0 to 1, or -1 to 1. In my case, I was…
-
StirTrek 2018 Talk: Machine Learning in R
I had the chance to speak at StirTrek 2018 about Machine Learning in R. I have been to StirTrek before, but it’s been a few years. The conference has really grown, as there are over 2000 attendees now. I was in the 3:30 timeslot. I talked in a full theater and they broadcast the talk…
-
Files and Pipes in R Video Demo
I’ve worked with various alternate file handlers in python before and wanted to explore the options in R. I was pleasantly surprised to find handlers prebuilt for tasks like compressing data. In addition, a pipe function is available to allow you to use less common commands on your file, like gpg for encryption. I put…
-
Markov Chain Simulation
I’ve been reading up on Markov chains and related concepts. On the wikipedia page there is an example of a 2 state Markov process. I decided to simulate it in R and plot the mean of the means. Quick Code example here: The mean of means (of state e) is close to .36. If you…
-
Text Processing in R Talk With the TM Package
I gave a talk at my local Cleveland R User Group about text processing and document vectorization. You can view the talk here: Note that I’m using the tm package, which is the traditional way to work with a document collection in R. There are new ways like tidytext that are gaining popularity. I may…