Category: Data Science
-
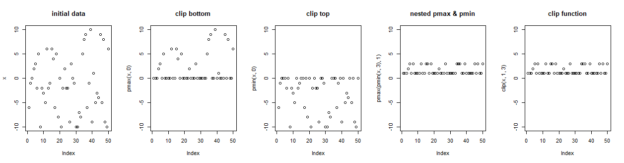
Equivalent of Numpy’s Clip function in R
Numpy’s clip function is a handy function that brings all data in a series into a range. For example, in machine learning, it is common to have activation functions that take a continuous range of values and bring them to a range like 0 to 1, or -1 to 1. In my case, I was…
-
Using Tensorboard with Multiple Model Runs
I tend to use Keras when doing deep learning, with tensorflow as the back-end. This allows use of tensorboard, a web interface that will chart loss and other metrics by training iteration, as well as visualize the computation graph. I noticed tensorboard has an area of the interface for showing different runs, but wasn’t able…
-
StirTrek 2018 Talk: Machine Learning in R
I had the chance to speak at StirTrek 2018 about Machine Learning in R. I have been to StirTrek before, but it’s been a few years. The conference has really grown, as there are over 2000 attendees now. I was in the 3:30 timeslot. I talked in a full theater and they broadcast the talk…
-
Hadoop: Accessing Google Cloud Storage
First, go here to choose the hadoop google cloud storage connector for your version of hadoop, likely hadoop 2. Copy that file to $HADOOP_HOME/share/hadoop/tools/lib/. If you followed the instruction in the prior post, that directory is already in your class path. If not, add the following to your hadoop-env.sh file (found in $HADOOP_CONF directory): #GS…
-
Hadoop: Accessing S3
This post follows in a series of doing local hadoop setup on macOS for development / learning purposes. In the first post, we installed hadoop. If you get stuck or need more detail, feel free to check out the apache docs on S3 support. First, we have to add the directory with the necessary jar…